ChatGPT Alternatives for Classification


LLMs like ChatGPT are increasingly being used not just for generative AI (“Write a poem about my dog”), but also for discriminative AI tasks (“What is in this photo?”). The latter has historically been bucketed under ‘machine learning’ using AI models like CNNs and RNNs.
One such discriminative AI task that LLMs now do is classification, or the process of categorizing images and text into discrete labels. You could build a classification model, for instance, that ingests images of plants and determines if they are wilting or healthy.

As a classification platform, we are often asked the pros/cons of using ChatGPT over traditional machine learning models. And, selfishly, we wish we could say, “There are none - use us!” But that’s not fair to ChatGPT. In many cases, it does make sense to use them. At the same time, using an LLM for classification has drawbacks, which could make it a non-starter for many companies.
Table of Contents
- Where does ChatGPT excel with classification?
- Where does ChatGPT struggle with classification?
- The 10 best classification alternatives
Where does ChatGPT excel with classification?
ChatGPT excels in two areas:
- Text analysis
- Image classification of information available on the Internet
Let’s dive into those.
Text analysis
Text analysis - also called Natural Language Processing (NLP) - involves analyzing text to understand everything from language to sentiment to NSFW words. And LLMs are pretty good at it out-of-the-box. This makes sense, though. LLMs need impressive text comprehension for reading inputs and outputting responses.
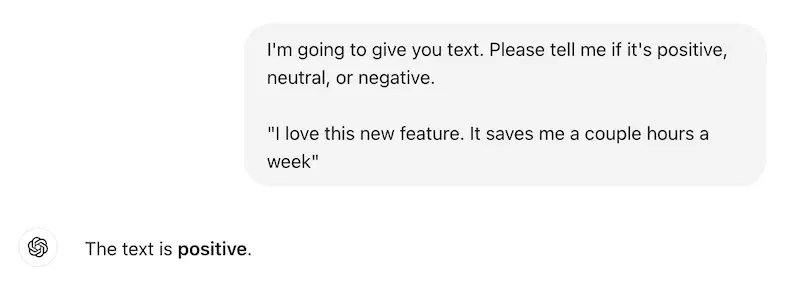
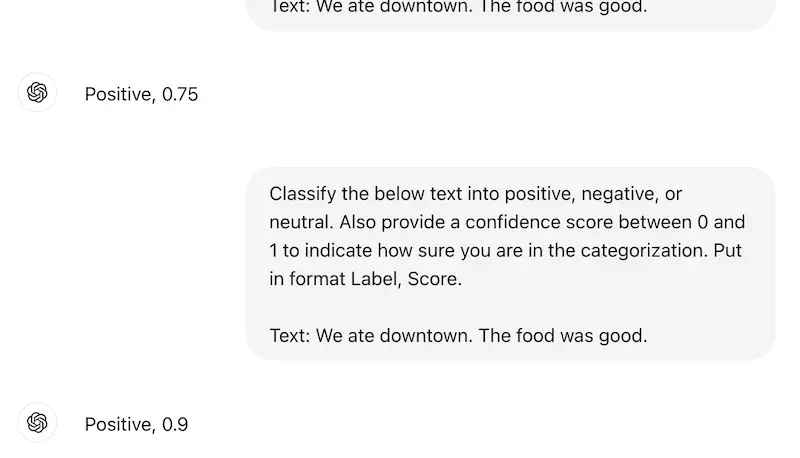
For instance, let’s use ChatGPT to analyze text sentiment with a zero-shot prompt. It has no trouble at all.
Notes:
- Zero-shot means we didn’t specifically train it with data, nor did we prime it with what to say. In other words, zero work is involved beyond writing the prompt.
- We use the UI here to make it more visual, but you could ask the same question through their API.
For AI, sentiment analysis is neither new nor groundbreaking, though. What about a slightly harder use case? Still spot on.

Image classification of general-knowledge information
A good example here is species identification, such as butterfly species. If you upload an image of a butterfly to ChatGPT and ask for the species, it has a high likelihood of being right. Which isn’t surprising. LLMs are trained on a vast corpus of data, which likely includes biological taxonomies.

This situation involves an open-ended response, as we aren’t giving ChatGPT a list of species to choose from. Sometimes this can be a good thing; there are 17,500 species of butterfly, for example, and building a traditional machine learning model with that many labels comes with difficulties.
Many times, though, using predefined labels is imperative, and you can certainly do that with ChatGPT by telling it the classes to choose from.

Why use ChatGPT for these use cases?
Beyond ChatGPT’s accuracy, there are two reasons to go with ChatGPT: (1) ease-of-launch and (2) a well-documented API.
For #1, a major historical pain with machine learning was the custom training of a model. While the number of samples needed for a decent model isn’t high (around 13 per class), the number can add up with many classes and/or higher accuracy needs. Collecting this data could be a non-starter.
So, the zero-shot capabilities of ChatGPT differentiate it greatly from traditional ML processes.
For #2, OpenAI’s API is well-maintained and well-documented. It’s simple to integrate and use. You should have no trouble integrating OpenAI into your workflow.
Where does ChatGPT struggle?
ChatGPT - like all LLMs - weren’t built for discriminative tasks. They can be repurposed, but they still struggle with certain use cases. Let’s address those.
Mediocre out-of-the-box accuracy
While ChatGPT excels at general text sentiment and broader knowledge classification, our testing showed that it struggled with accuracy for real industry use cases (you can read the full analysis here)
Across 12 of our customer datasets, for example, ChatGPT’s zero-shot accuracy was 65%, compared to 82% using a trained model. Given it had no training samples, 65% is impressive, but it’s far from the accuracy you’d want for production-level usage.
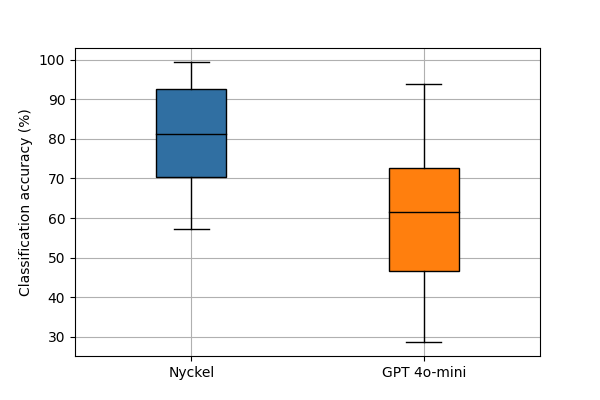
Does this mean that ChatGPT wouldn’t work for you out-of-the-box? No. But it does indicate that, on average, you’ll see better accuracy if you train your own model.
Iteration and accuracy improvements
Which brings us to the next ChatGPT limitation: if your ChatGPT accuracy isn’t where you want it, there’s not much you can do. Outside of new ChatGPT releases (which may or may not help), the model isn’t going to suddenly start delivering better accuracy. If zero-shot is stuck at 65% accuracy, that’s likely your ceiling.
Of course, like we mention earlier, you could theoretically add more and more annotated examples to the prompt itself, hoping that those samples improve the accuracy. And maybe they would. But this also increases costs and complexity, and the more rules ChatGPT has to follow, the more likely it sees degraded performance.
With custom-built machine learning models, though, you control the training process. If the accuracy isn’t to your liking, then just upload more training samples and watch the model improve.
If accuracy is your top concern, then, you should build your own model. Having the power to improve it grants you more control, making it a more reliable and scalable long-term option.
Custom business-specific problems, especially with images
LLMs were built predominately on public data. What happens with private data? It struggles.
Take this example, where you want to classify images into the right SKU.

Obviously, SKU-level data is particularly niche, but LLMs struggle with broader examples too. Imagine running a dating app, where you have strict rules about what’s allowed in profile photos, such as requiring the main profile pic to be a non-cropped, forward-facing headshot.

Without sending your entire community guidelines in each prompt, ChatGPT will take a best guess, likely based on rules other sites/apps have. It would no doubt say a porn image is not allowed, but would have trouble understanding rules that are particular to certain platforms / situations.
Of course, you could add the rule to the prompt. ChatGPT should have no issue answering correctly.
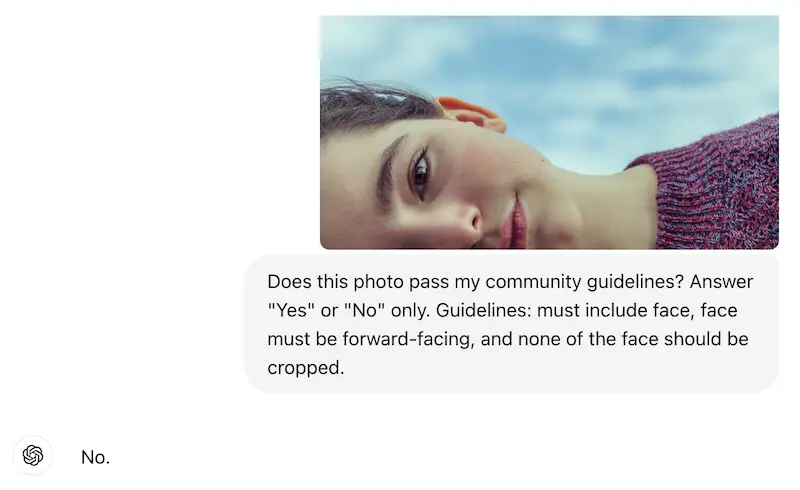
But what if you have 10, 20, 50 different small rules? You could add all of them to each prompt, but that increases the # of used tokens, leading to higher costs and additional maintenance. Additionally, the model’s ability to consistently apply complex, context-specific instructions may degrade with more rules, impacting accuracy.
In this world, you’re better off training a custom model using a classification platform, not an LLM. With these, you can define your labels (such as ‘Allowed Photo’ and ‘Not Allowed Photo’) and train the model on what it should look for or not.
Inconsistent response formatting
When doing classification with an LLM, you need to be specific about how you want the answer, in what format, using what labels, etc. But even if you have devised the perfect prompt, ChatGPT rarely follows it 100%. Let’s take this example. We asked it the same question 5 times, and the response wasn’t always the same format.
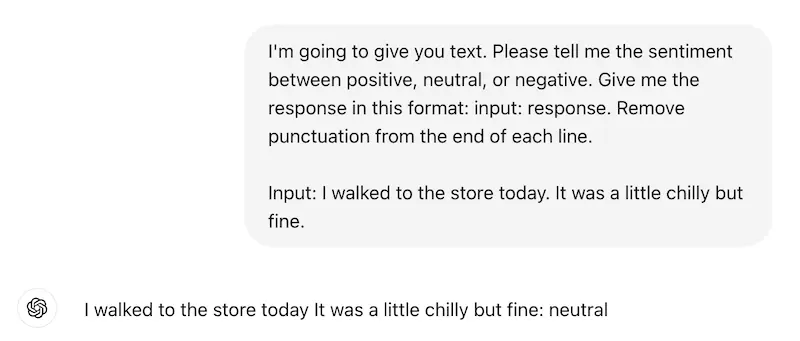
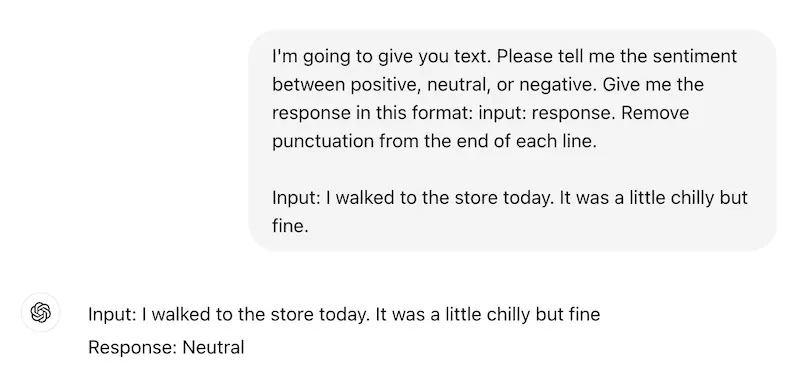
If you’re expecting a specific answer format, which is then fed into your workflow, a slightly-different (though semantically similar) response could lead to hard-to-troubleshoot breakdowns.
This could lead to a cat-and-mouse prompt game where you add more and more instructions to ensure the right response, increasing token use without ensuring 100% accuracy.
Discriminative models, on the other hand, will return only the label. They aren’t trained to add anything else. This ensures that the response will always be in the preferred format, never misspelled, and easy to troubleshoot.
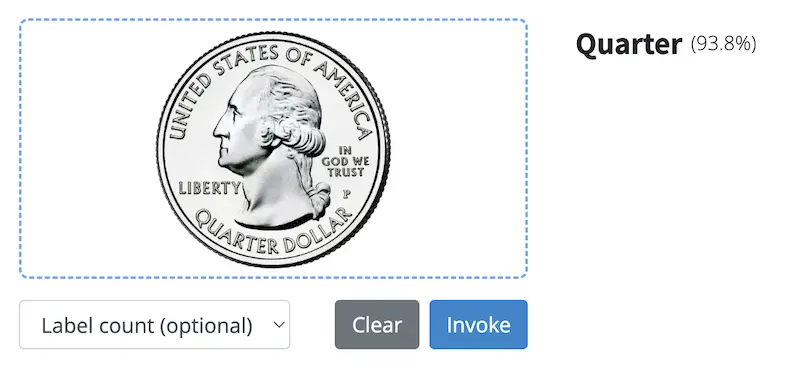
Confidence scores
When classifying, a machine learning model will provide a ‘confidence score’ that highlights how confident it is in the accuracy of that label. These scores range from 0 to 1, often represented as a percentage (0% to 100%), with a higher score meaning the model is more confident that the label is right. While you may not employ them, they are pivotal in certain use cases like content moderation, where high confidence results will get auto-marked, while anything with, say, < 90% would be flagged for manual review.
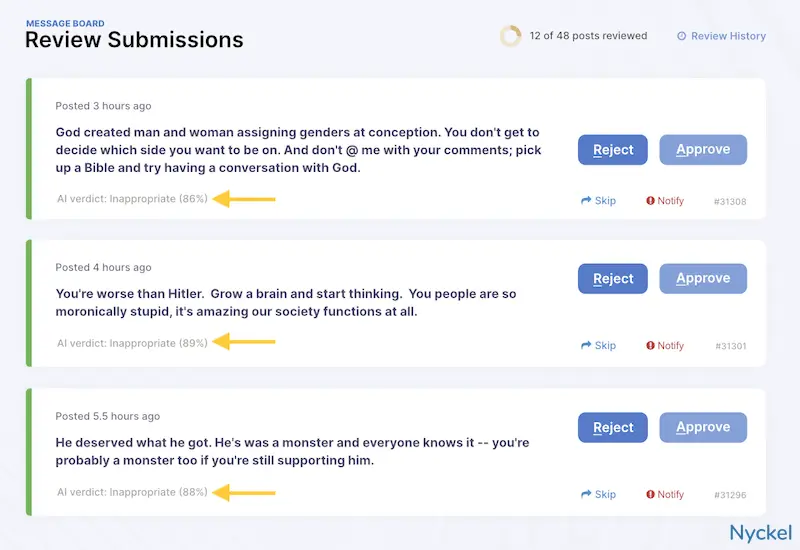
ChatGPT won’t return this score by default, but you can ask for it. Unfortunately, ChatGPT’s score struggles with accuracy, which we touch upon here.
Basically, ChatGPT often returns a high confidence score when it’s wrong. This isn’t to say that machine learning models are always right - but often when their classification is wrong, the confidence scores will reflect uncertainty about the result. A confidence score of 51% in a binary classifier, for instance, tells you that the model is effectively as confident as a coin flip. That’s data that could flag a manual review or otherwise be used in your workflow.
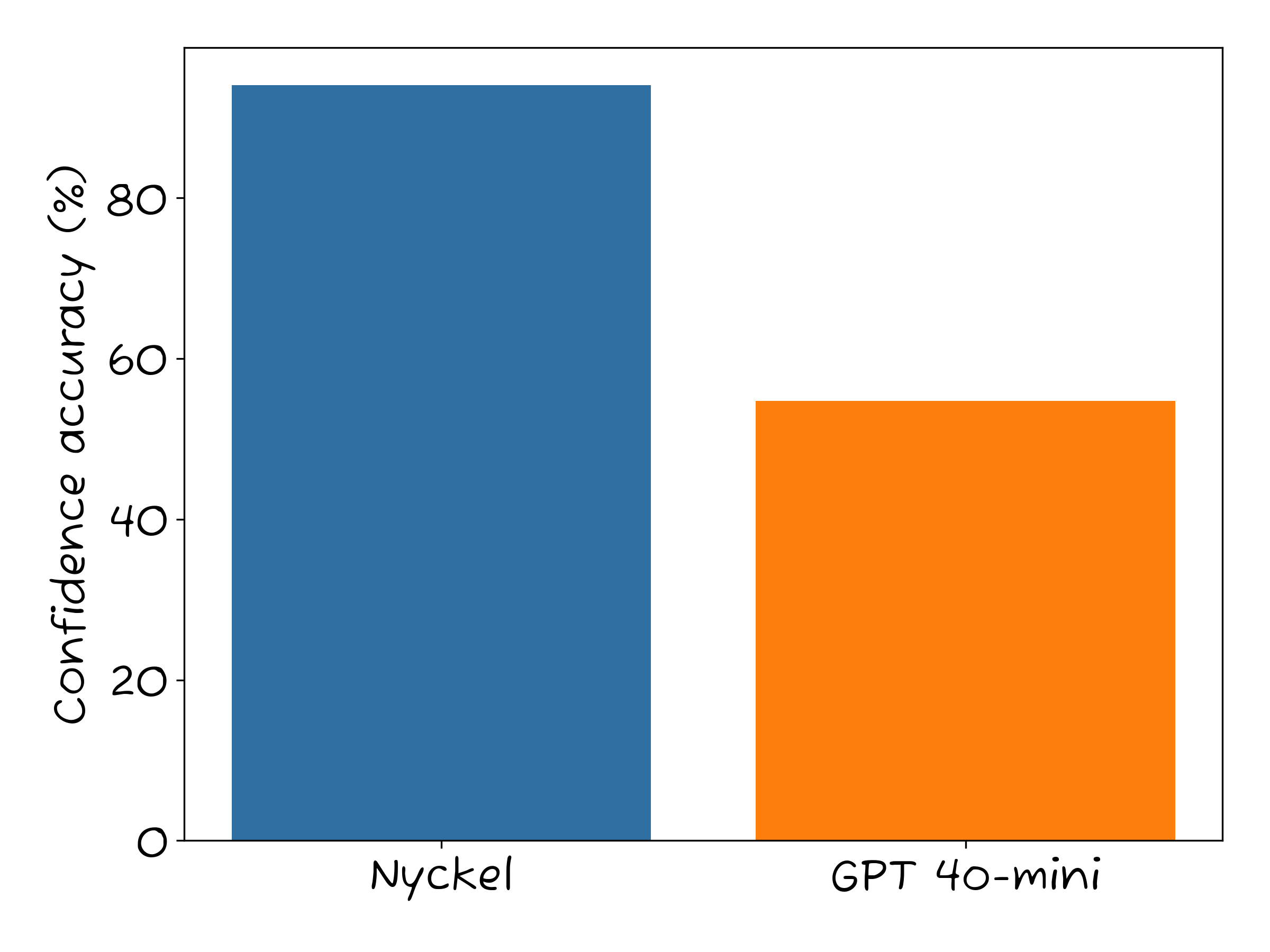
But if you can’t trust ChatGPT’s confidence scores, you must operate without them. That may be fine for many use cases, but it isn’t ideal if you’d like to use that score.
We’ve also found that ChatGPT’s confidence scores can vary quite a bit for the same prompt. Not wildly, but enough to be concerning if you’re using the scores at scale.
Sample management and annotation tools
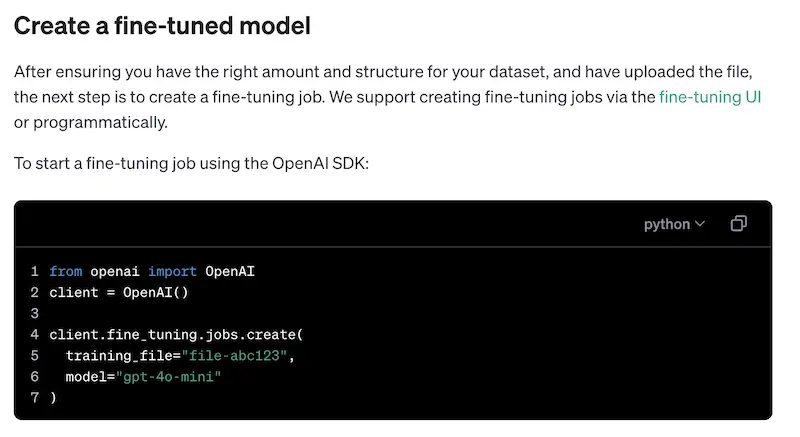
Our earlier comments focus on ChatGPT’s zero-shot functionality (aka, ping it with a random prompt, get a response). But OpenAI does have a capability to train and fine-tune custom models, which obviates the accuracy concerns of above (however, the confidence scores remain off).
This functionality puts OpenAI on par with other AutoML (automated machine learning) solutions, which allow businesses to create custom models from trained data. Like AutoML tools, it involves uploading training samples, waiting for the model to train, then sending a request for classification. This is a departure from the normal zero-shot approach people associate with ChatGPT.
Unlike many other AutoML tools, OpenAI has no UI for training data management or easy fixing of annotations. Think there was a labeling error? There’s no way to tell within ChatGPT’s UI, so you must find the raw file, fix it if needed, then re-upload the folder to ChatGPT. If you’re a solo engineer, this wouldn’t be the worst, but imagine you have a team of 15 people with multiple annotators. Having a cloud UI where anyone can fix broken labels could save time and headaches.
It’s hard to impart just how valuable a UI can be for classification management. Even if 90%+ of the process is automated via APIs/SDKs, the UI provides a way for anyone on the team to:
- Do quick audits of uploads to see if anything is amiss.
- Identify holes in your model. A UI that shows you accuracy by label can be immensely helpful in understanding what labels to flesh out.
- See incoming invokes/inferences to understand real-world usage and improve the model. Also known as active learning, this is a built-in feature that Nyckel provides, which captures new content the model has classified, then surfaces it to you for auditing.
If not ChatGPT for classification, what are the alternatives?
If you’re struggling with ChatGPT for classification, you are not alone. Many of our customers are ex-OpenAI users. If ChatGPT isn’t working for you, you have a few high-level alternatives:
- Build your own
- Use an AutoML classification vendor
- Use a pretrained classification API
Build your own
You can build your own classification model using a variety of tools. Theoretically you can build it entirely from scratch by writing your own algorithm and connecting directly with a Convolutional Neural Network (CNN) or a similar model.
More likely, though, you’ll abstract that complexity by using a ML framework like PyTorch or Keras and/or use a ML-Ops infrastructure tool like AWS SageMaker.
Pros:
- Complete control - You have full control over the model, from the architecture to the training process.
- Community support - These tools come with plenty of resources and documentation.
Cons:
- Time-consuming - It requires a significant time and effort commitment.
- Requires expertise - This path is a non-starter if you don’t have extensive machine learning experience already.
- No to minimal user interface (UI) for management - Makes it harder to visualize performance and improve the model.
- Hard to troubleshoot - When handling everything including data preprocessing, model design, training, and evaluation, it may be hard to troubleshoot issues.
- Scalability concerns - If you’re handling billions of monthly classifications, it could be hard to maintain uptime.
Using an AutoML classification platform
You can also launch a classifier with an AutoML machine learning tool (generally sold as software-as-a-service). They abstract the work involved — such as pre-processing and algorithm design — which greatly reduces time to deployment. They also include an out-of-the-box UI for sample management and accuracy tracking.
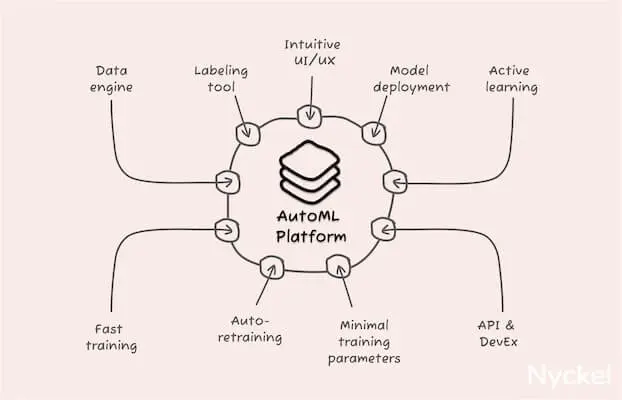
Pros:
- User-friendly UIs - UIs make it easy to track your progress, identify inaccuracies, and fine-tune as needed.
- Quick deployment - You can deploy a model in less than a day (with some, in just minutes).
- Less machine learning experience needed than DIY path - While the complexity will vary by tool, these solutions nonetheless aim to minimize the ML complexity.
- Maintenance - The vendors will troubleshoot and fix bugs for you.
- Scalable - It’ll be on the tool to handle scale and uptimes.
Cons:
- Cost - Can be expensive, especially for high-volume use cases.
- Less architecture customization - You won’t have as much control over the underlying algorithm or how the model is structured.
- Data privacy - Any time you send data to a third-party, there are security risks.
Use a pretrained classification API
Rather than building a classification model, you can also always hook into a pretrained classifier, like those offered by Nyckel. These generally operate as black boxes, where you ping the API with the image, and it’ll return the label and confidence score. While not customizable or ideal for bespoke use cases, they can be good for commoditized datasets, like porn identification.
Pros:
- Fast to launch - Can take just minutes to integrate.
- No machine learning knowledge needed - If you can code to an API, you’re good.
Cons:
- Most don’t offer fine-tuning - If these models don’t have the accuracy you want, you can’t customize them. The one exception is Nyckel, which allows you to copy the model and add your own training samples, giving you control over future iterations.
- Limited number available - On Zyla, for instance, there are just 16 image classification APIs available. Nyckel has a bit more, at 6,000 and counting.
- Not for custom use cases - These are useful for certain situations — like color tagging or content moderation — but won’t work for custom computer vision use cases.
Top ChatGPT alternatives for classification
If you’re looking for specific vendor recommendations, below lists the top 10 alternatives to ChatGPT for classification. They are not interchangeable. Some only do image classification, for example. But as a group, you should be able to find a solution for your needs.
Nyckel
Nyckel provides a classification API that makes it easy to launch a classification model in minutes. This is true regardless of how much training data you have. Get started quickly with our pretrained classifiers or zero-shot model creation (just input labels and start invoking!). Alternatively, you can create your own model by uploading your own training data. Create, iterate, and delete through our UI, API, or SDK.
Pros:
- Real-time training - The model automatically updates after every change, making it easy to fine-tune and iterate.
- 100s of pretrained classifiers - Don’t want to build the model yourself? Connect with our 150+ already-built classifiers.
- Elastic Pricing - You only pay for usage versus the more-confusing “always-on” node pricing that most tools use.
- API-approach makes it developer friendly - Many AutoML tools are not API-first, forcing customers to work through the UI. Nyckel has API / UI parity.
- Streaming API - Unlike other batch API tools, Nyckel’s API offers real-time creation of functions, uploading samples, and invoking.
Cons:
- Not as many bells and whistles as other solutions - Nyckel focuses on supervised classification (defined labels), so doesn’t work well for unsupervised analysis of text or images.
- No customization of model’s algorithm - The decision to abstract the machine learning complexity does mean there’s no way to adjust the foundational model algorithm.
Google Vertex AI
Google Vertex AI is Google’s unified data and AI platform. While powerful, it comes with a steep learning curve, and the initial setup and labeling process can be complex. Still, its integration with the broader Google ecosystem can be advantageous for those willing to invest time in the learning curve.
Pros:
- Rich library of help docs - Google does a great job at creating explainer videos and guides if you get stuck. Additionally, there’s a broader Google community that actively shares ideas and recommendations.
- Backed by Google - Nobody got fired for buying from Google. It’s a safe route, even if not the easiest.
Cons:
- Steep learning curve - Unless you are already well-versed in Google’s developer products, their dashboard can be difficult to navigate.
- Slow to train / build - Each time you want to train, even for a small dataset, it can take hours. Larger datasets can take 24 hours or more. This makes real-time fine-tuning impossible.
Amazon Rekognition
Amazon Rekognition offers customizable computer vision APIs. While the setup process can be tedious, the platform’s interface simplifies the training process. However, it requires coding for deployment, so it’s not ideal for those without coding expertise.
Pros:
- Great for machine learning experts - Amazon provides granular controls for manipulating your algorithm and models. If you know how to work them correctly, you get a lot of flexibility.
- Backed by Amazon - You can trust that Amazon will continually improve their product and offer extensive integration guides.
Cons:
- Tedious set-up - Unlike more turnkey AutoML vendors on this list, Rekognition is confusing and time-consuming to set-up. Deployment also requires extensive coding versus a simple API call.
- ML experience is not a must, but it’s recommended - The flipside of a robust feature set is that managing them can be difficult unless you understand ML well.
Amazon Comprehend

Amazon offers its own natural language processing solution called Comprehend. While the setup process can be tedious, the platform’s interface simplifies the training process. However, it does require coding for deployment, so it’s not ideal for those without coding expertise.
Pros:
- Great for ML experts - Amazon provides granular controls for manipulating your algorithm and models. If you know how to work them correctly, you get a lot of flexibility.
- Backed by Amazon - You can trust that Amazon will continually improve their product and offer extensive integration guides.
Cons:
- Arduous set-up - Unlike more turnkey AutoML vendors, Comprehend is confusing and time-consuming to set-up. Deployment often requires complicated coding versus a simple API call.
- ML experience is not a must, but it’s recommended - The flipside of a robust feature set is that managing them can be difficult unless you understand ML well.
Hugging Face AutoTrain
Hugging Face AutoTrain allows you to quickly build classification models through their open-source tool. It offers pretrained models and fine-tuning options, making it suitable for various applications.
Pros:
- Integrated with the Hugging Face ecosystem - Hugging Face is major playing in the ML space, with a large community that uploads free models, ideas, and datasets.
- Great for open-source lovers - Hugging Face makes it easy to publish your models to the open web, allowing you to share and solicit feedback easily.
Cons:
- Still requires some technical knowledge - You can view Hugging Face as the Github of Machine Learning. Just as Github requires some basic technical know-how (such as how to spin up a repo and edit code), Hugging Face requires some basic coding skills.
- Focused on open-source - Businesses that want a more hands-on, closed experience may not enjoy Hugging Face’s open-source philosophy.
Ximilar
Ximilar specializes in computer vision, providing user-friendly tools and pretrained models. Its drag-and-drop interface streamlines data import and labeling, while model training takes around 20 minutes.
Pros:
- Good accuracy - In our image classification benchmark, Ximilar was one of three tools that had a 100% accuracy (alongside Nyckel and Azure).
- Lots of pretrained classifiers - These tools focus on product tagging and trading card classification.
Cons:
- No large user community - Unlike other vendors on this list, there’s no robust user community for soliciting ideas and support.
- Pricey - Their second tier (Professional) can cost as much as $3,435 per month.
Roboflow
Roboflow focuses on computer vision, offering a drag-and-drop interface for image and video upload. Their model training is efficient, taking just six minutes in our testing, although it can take a while for a new user to get to the training step.
Pros:
- Built for machine learning enthusiasts - Roboflow offers many product types and fine-tuning tools, making it extensible, though complicated. This makes them a good tool for ML experts, but less appealing to non-devs.
- Great user community - Roboflow has tens of thousands of user-generated datasets and public models (access to these are free for anyone who signs up).
Cons:
- Steep learning curve - The Roboflow UI, while sleek, is complicated, with many options to choose from in each step. It can take a while to get used to.
- Not focused on image classification - While they offer image classification, it’s often downplayed in favor of “more interesting” use cases like real-time object tracking in videos.
Azure Custom Vision
Microsoft’s Azure Custom Vision touts itself as enabling users to create “state-of-the-art” computer vision models easily. They list Volpara Solutions, Honeywell, and Pepsi as customers.
Pros:
- Backed by Microsoft - Like the other behemoths on this list, Azure has a strong prebuilt community and reliable infrastructure.
- Accurate - In our research, Azure was just one of three solutions (alongside Nyckel and Ximilar) with perfect accuracy ratings.
Cons:
- Steep learning curve - Like Amazon and Google, Azure is not an intuitive tool, and a knowledge of ML and the Azure ecosystem is pivotal to getting launched quickly.
- Confusing pricing - Their pricing is convoluted and depends on your region, the number of API calls, training per compute hour, and image storing needs.
Clarifai
Clarifai calls itself many things: a generative AI platform, LLM platform, computer vision platform, and full stack AI platform. Its customers include Acquia DAM, Foap, and OpenTable.
Pros:
- Large offering - Clarifai offers a full suite of AI tools, from discriminative to generative.
- Clean UI - Their UI is streamlined and intuitive.
Cons:
- Confusing terminology - In many instances, Clarifai has coined terms rather than use industry standard ones. For example, Clarifai calls image labels “concepts,” and it can take a while to sort through their Clarifai-specific classifier names to figure out what you actually need.
- Low accuracy - In our image classification benchmark, Clarifai had just a 70% accuracy, and the images it got right had low confidence scores.
Keras / Tensorflow / PyTorch
These three tools are all open-source machine learning frameworks. They make building your own machine learning model simple, but they don’t abstract it completely, so you still need a deep understanding of ML to launch.
Pros:
- Full control - You can adjust nearly all parts of the model. Compared to the AutoML vendors on this list, you have much more control over the nuances of the algorithm.
- Cost-effective - Outside of opportunity cost, hosting your own model tends to be cheaper than a third-party vendor.
Cons:
- Requires machine learning experience - If you don’t have a ML background, it’ll be hard to get going.
- Time-consuming - Even if you have ML experience, there’s a major time and effort commitment.
Next steps to finding a classification alternative to ChatGPT
If ChatGPT isn’t working for your classification use case, we highly recommend an alternative approach.
And if you’d like to create a classification model in just minutes, try Nyckel. Our solution lets you build an accurate custom model no matter how many training samples you have.