Classification using LLMs: best practices and benchmarks

Introduction
Large Language Models (LLMs) have a wide range of applications, from generating human-like text to performing complex reasoning tasks. In this post we look at the use of LLMs for classification tasks and compare it to traditional transfer learning methods. In particular we focus on so-called “zero-shot” classification where the model is asked to classify text without any examples. We also look at “few-shot” classification, where a few examples are provided in the prompt.
We’ll investigate the following aspects:
- How accurate is zero-shot classification on production datasets?
- How much does adding a few in-prompt examples help?
- How important is it to ask the LLM to “reason” about the task?
- How important is it to provide the context of the task?
- How much does using a larger model help?
Data
We use 12 text classification datasets from our production database. These are real customer use-cases spanning several industries: lead scoring, spam filtering, content moderation, sentiment analysis, topic categorization, and more. Each dataset has between 1,000 and 10,000 annotated samples and between 2 and 10 classes.
Each set is split 70%/30% into test and train sets. The train set is used for the transfer learning baseline and for the few-shot learning experiments. The test set is used to evaluate the performance of each method.
GPT prompting template
We use the Chat Completion API from OpenAI with the following template.
response = self._client.chat.completions.create(
model=self._model_name,
messages=[{"role": "system", "content": prompt}, {"role": "user", "content": content}],
temperature=0.7,
max_tokens=4096,
top_p=1,
)
Here content is the text content to be classified, and prompt is the prompt to the model. We use the following prompt template:
You will be provided with a {text_type}, and your task is to classify it into categories: {label_list}.
You should also provide a confidence score between 0 and 1 to indicate how sure you are in the categorization.
End your reply with a json-formatted string: {"label_name": "category", "confidence": <float>}
text_type can be, for example, “news article”, “tweet”, “customer feedback”, etc. label_list is the list of classes in the dataset.
The LLM reply is then parsed from a JSON body and the predicted class and confidence are retrieved. For the purpose of this post, we disregard the confidence scores. We refer to this post for a detailed discussion and analysis of the confidence scores from LLMs.
Transfer learning baseline
To put the LLM classification accuracy in context we use a simple transfer learning baseline. First we use several pre-trained language models, like Distilbert, Sentence Transformers, FlagEmbeddings and others to extract features from the text content. A Logistic Regression classifier is then trained on the features, and we pick the best one for each dataset to represent the transfer learning baseline.
Results
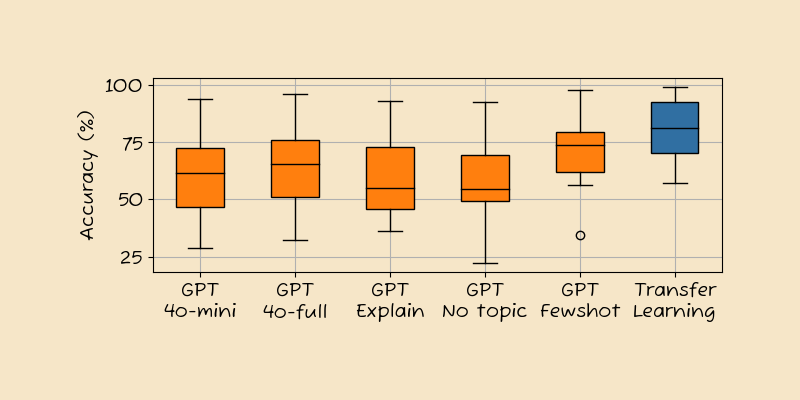
Zero-shot classification is easy, but not very accurate
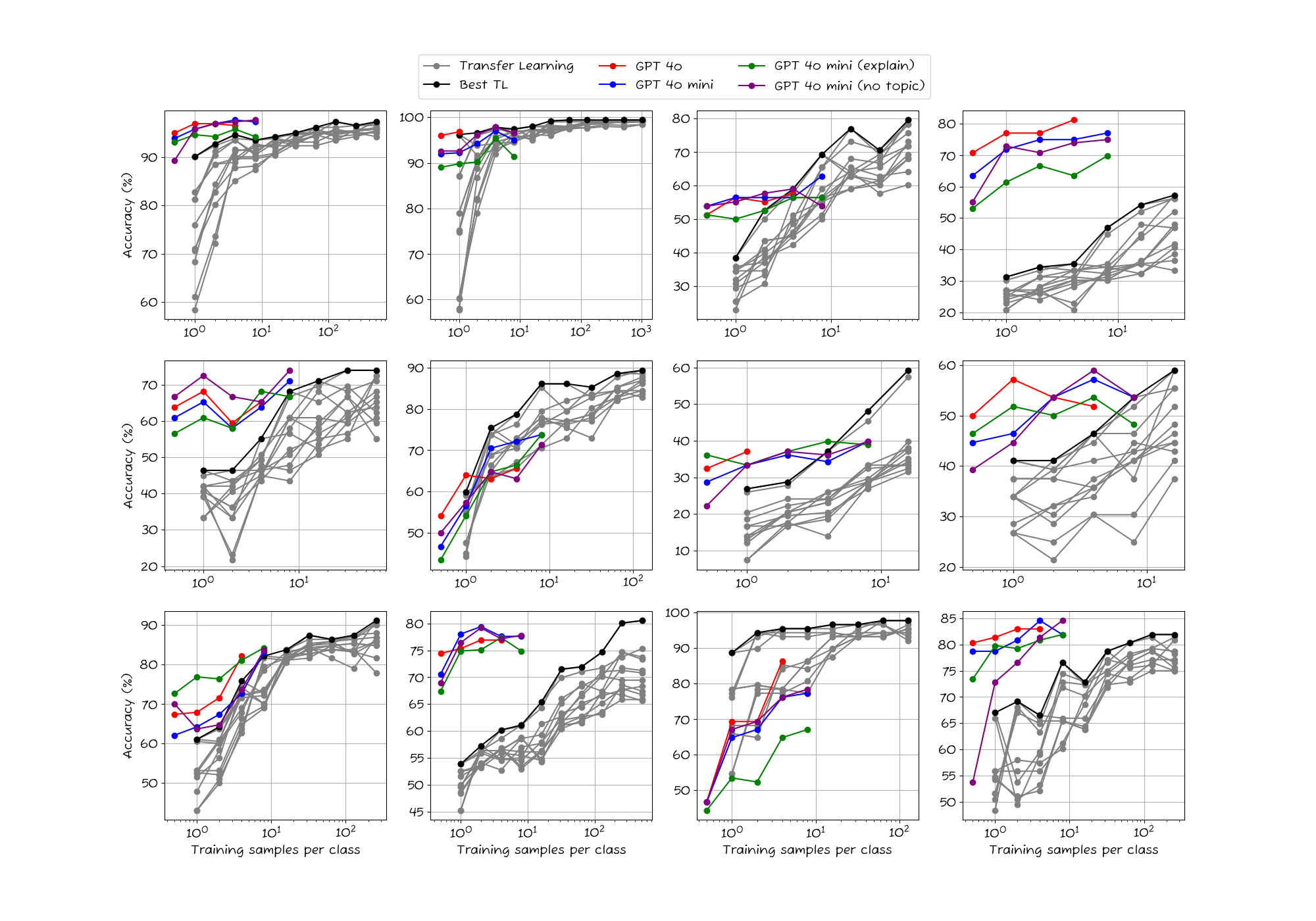
We start by comparing the accuracy of the zero-shot classification to the transfer learning baseline. As shown below, the zero-shot performance, while impressive, is equivalent to using roughly two annotated samples per class. After that, the transfer learning baseline continues to improve, approaching 100% at 1000 samples per class.
Accuracy results across 12 production datasets. Transfer learning results uses supervision.
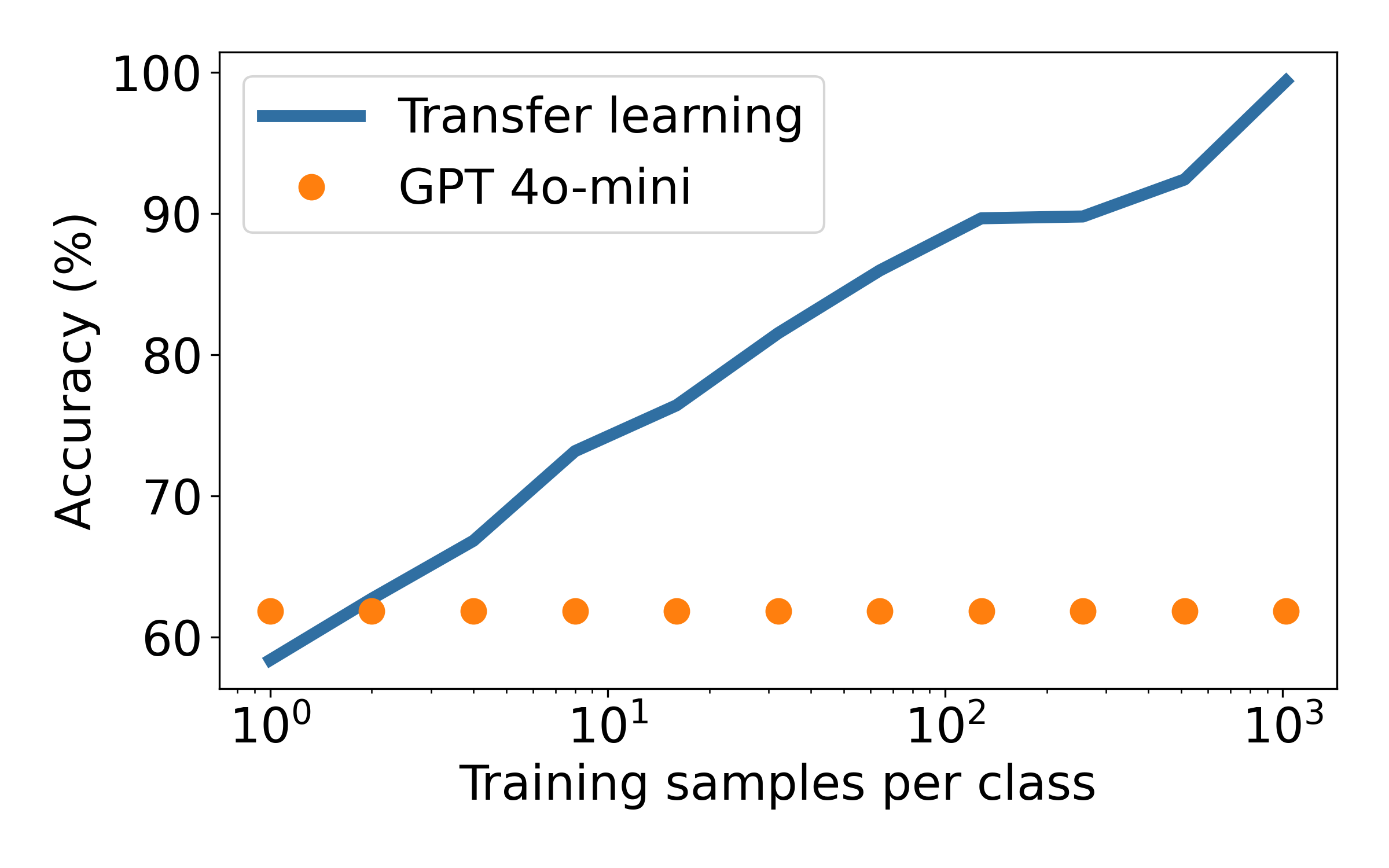
Few-shot learning helps, but only up to a point
We now look at the few-shot learning results. We include 1 to 8 examples per class in the prompt in order to improve the accuracy of the LLM.
Including a single example per class is helpful. The average accuracy increase from ~62% to ~68%. Adding more examples help further, but at a slower rate than adding them to the transfer learning baseline. After around 10 examples per class, the transfer learning baseline wins out. Note: we had to abort the few-shot experiment after 8 examples per class, as it was taking too long to run.
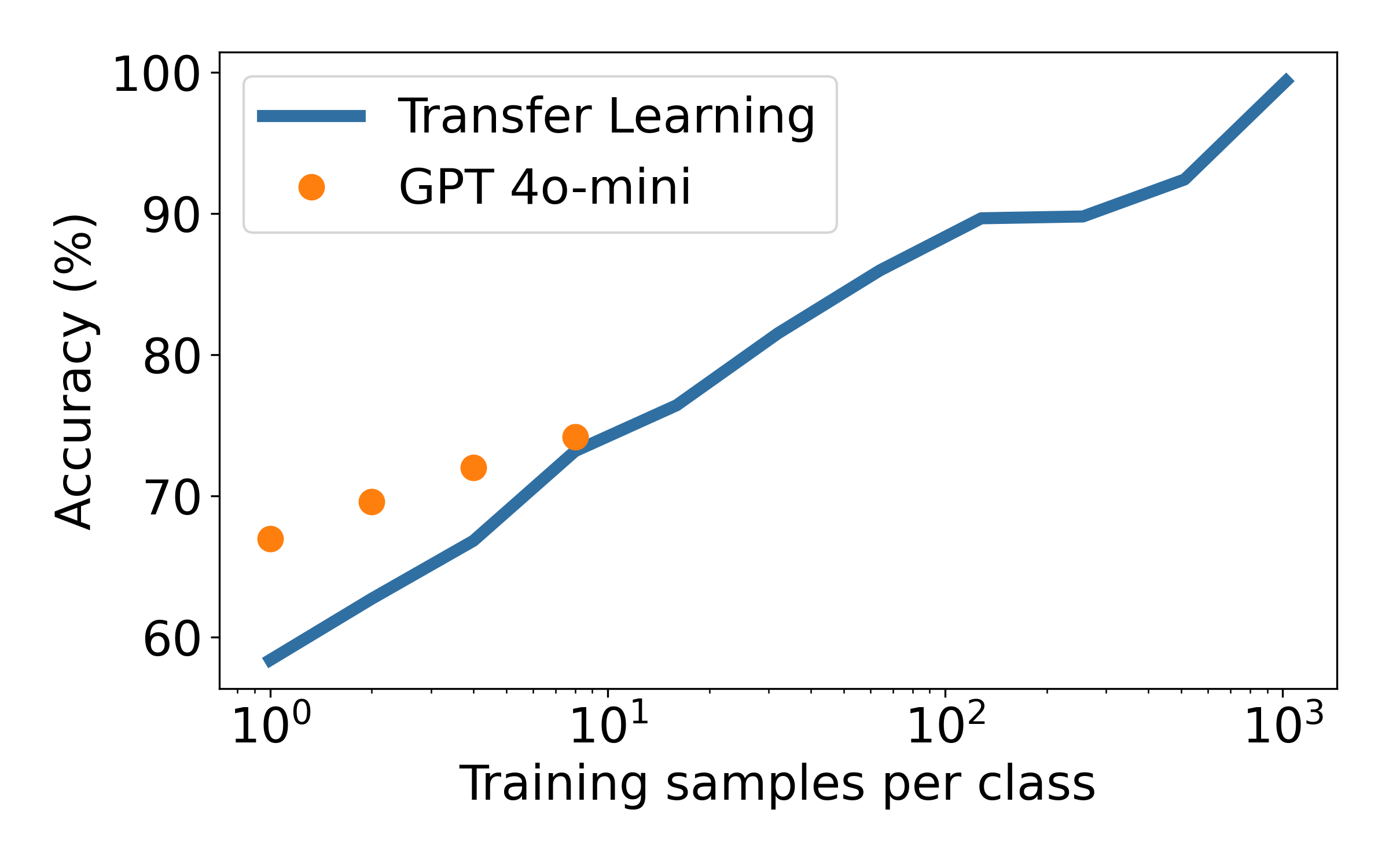
Accuracy results across 12 production datasets. Transfer learning results uses supervision.
Prompting for reasoning does not help
Other studies on LLM for classification have suggested that the accuracy improves if the LLM is asked to reason about the task at hand. We test this by asking the LLM to explain its reasoning. We use the same prompting template as above, but inserted a note asking for a brief explanation of the choice.
"Please provide a brief explanation of your choice before your reply."
Somewhat surprisingly, we find that prompting for reasoning does not improve the accuracy of the LLM. In fact, it is slightly worse than the baseline.
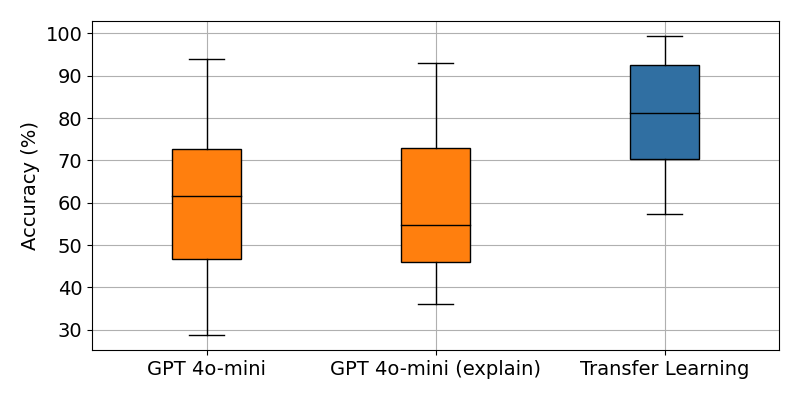
Accuracy results across 12 production datasets. Transfer learning results uses supervision.
Providing context helps, but not much
In the prompt template we provide a text_type, such as “news article”, “tweet”, “customer feedback”, etc. We hypothesize that providing the model with the type of text it is about helps. After all, the model has been trained on a wide array of text types, and perhaps it is not able to generalize to the specific type of text in each dataset. So in this experiment, we replace the text_type with the generic word text instead.
The results confirm our hypothesis: providing the model with text details helps, albeit only marginally.
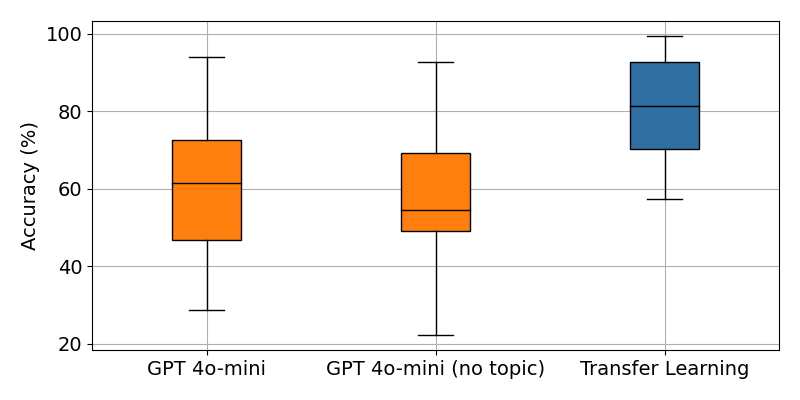
Accuracy results across 12 production datasets. Transfer learning results uses supervision.
Using full-size LLM helps marginally
So far we have used the gpt-4o-mini model, which is a smaller, faster, and cheaper model than the full-size gpt-4o. What happens when we use the latter?
As we can see, the full-size model performs better than the mini model, going from ~62% to ~67%. However, gpt-4o is ~25x more expensive than gpt-4o-mini, so is that incremental improvement worth the much-higher costs?
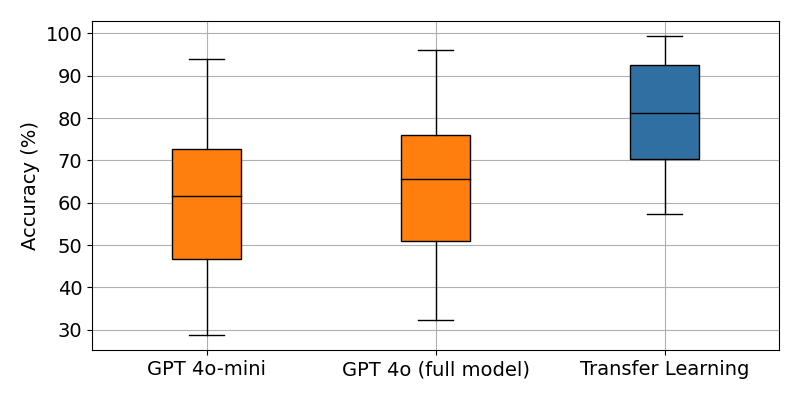
Accuracy results across 12 production datasets. Transfer learning results uses supervision.
In summary
We’ve run experiments on using LLM for text classification with 12 real-world text classification datasets. We have compared the accuracy of zero-shot, few-shot, and transfer learning. We have also looked at the impact of providing the model with the type of text it is about, and the impact of using the full-size model. In summary::
- Zero-shot classification is not very accurate.
- Few-shot learning helps, but only so far.
- Asking the LLM to explain its reasoning did not help.
- Providing the model with the topic of the text helps marginally.
- Using the full-size model improves the zero-shot accuracy marginally.
Full results with all details can be downloaded here.
{kind=link}
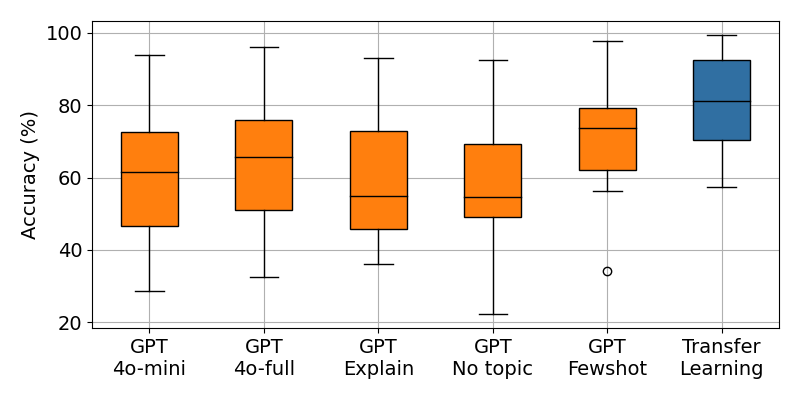
Fewshot uses 4 examples per class, Full model uses gpt-4o, No topic uses the generic 'text' topic, Explanations asks for a short explanation of the choice. Transfer learning uses between 16 and 1024 samples per class depending the dataset.
In conclusion
Using LLMs for classification tasks is a quick way to get started, but is not very accurate. Transfer learning does significantly better but requires training data and siginficantly more development work. You can learn about additional pros/cons of LLMs vs transfer learning here.
Ultimately, if you want the simplicity of zero-shot LLM classification AND the accuracy of a custom-built model, your best bet is an AutoML service like Nyckel, which abstracts the complexity of building and hosting, letting you launch high-accuracy models in just minutes.