How Nyckel is Redefining AutoML


Machine learning is rapidly evolving, and automation is upending model development. Even AutoML - technology that simplifies custom ML model creation - is transforming. This post explores the AutoML landscape and highlights how Nyckel is disrupting traditional AutoML approaches.
For instance, in our below benchmark of Nyckel vs popular AutoML platforms, our approach delivers similar accuracy as competitors, but requires 100x fewer annotated samples (100 vs 10,000+)!

What is AutoML?
AutoML (Automated Machine Learning) systems evaluate and train multiple machine learning models on your dataset automatically. It eliminates the painstaking process where data scientists manually test countless models and fine-tune parameters to achieve target accuracy.
Indeed, why invest months in manual testing when you can train hundreds of models in days (or hours)? This innovation ultimately makes machine learning accessible to teams without specialized expertise.
The Three Types of AutoML
The AutoML ecosystem can be divided into three distinct approaches:
1. Transfer Learning-Based AutoML
This approach uses pre-trained neural networks as feature extractors. These networks have already learned representations from massive datasets like internet-scale image collections. The workflow typically involves:
- Running data through several pre-trained networks to extract features
- Training lightweight models (logistic regression, random forests, etc.) on these extracted features
- Picking the combination that performs best
Transfer learning systems produce compact model artifacts and deliver impressive speed. We built Nyckel on this approach because it hits the sweet spot between performance and practicality.
2. Fine-Tuning-Based AutoML
This modifies pre-trained networks by adjusting their weights for your specific dataset. The automation handles:
- Attaching classification layers that match your specific outputs
- Testing various optimizers like Adam or SGD
- Adjusting learning rates and other training parameters
- Applying data augmentation strategies where appropriate
Fine-tuning can squeeze out higher accuracy, but creates bulky model artifacts (often 300MB-1GB). This bloat introduces real-world problems: slow cold starts (10-20 seconds), higher hosting costs, and the need for always-on infrastructure.
3. Neural Architecture Search (NAS)
The most ambitious flavor of AutoML designs neural architectures from scratch. NAS systems experiment with:
- Network topology - adding or removing layers
- Connection patterns between layers
- Layer types and configurations (convolutional, transformer, etc.)
- Activation functions and other architectural details
While NAS offers unlimited customization, it struggles with combinatorial complexity and computational demands. Without pre-trained weights, these systems essentially start from zero rather than leveraging the knowledge embedded in existing networks.
The Nyckel Approach: Transfer Learning-Based AutoML on AWS Lambda
Most AutoML platforms use a handful of GPU servers processing data in sequence. We took a different path, building on AWS Lambda to achieve massive parallelization. Our architecture looks nothing like traditional ML infrastructure:
Feature Extraction
When training begins:
- The system creates feature extraction coordinators for each network type (DINOv2, CLIP, etc.)
- Each coordinator spawns up to 500 worker nodes that process individual data points in parallel
- With extraction averaging ~200ms per sample and hundreds of parallel workers, we can process 100K samples in minutes
- All extracted features go into persistent storage, creating a reusable feature cache
- For new data added to existing functions, we only extract features for those new points and append them to storage
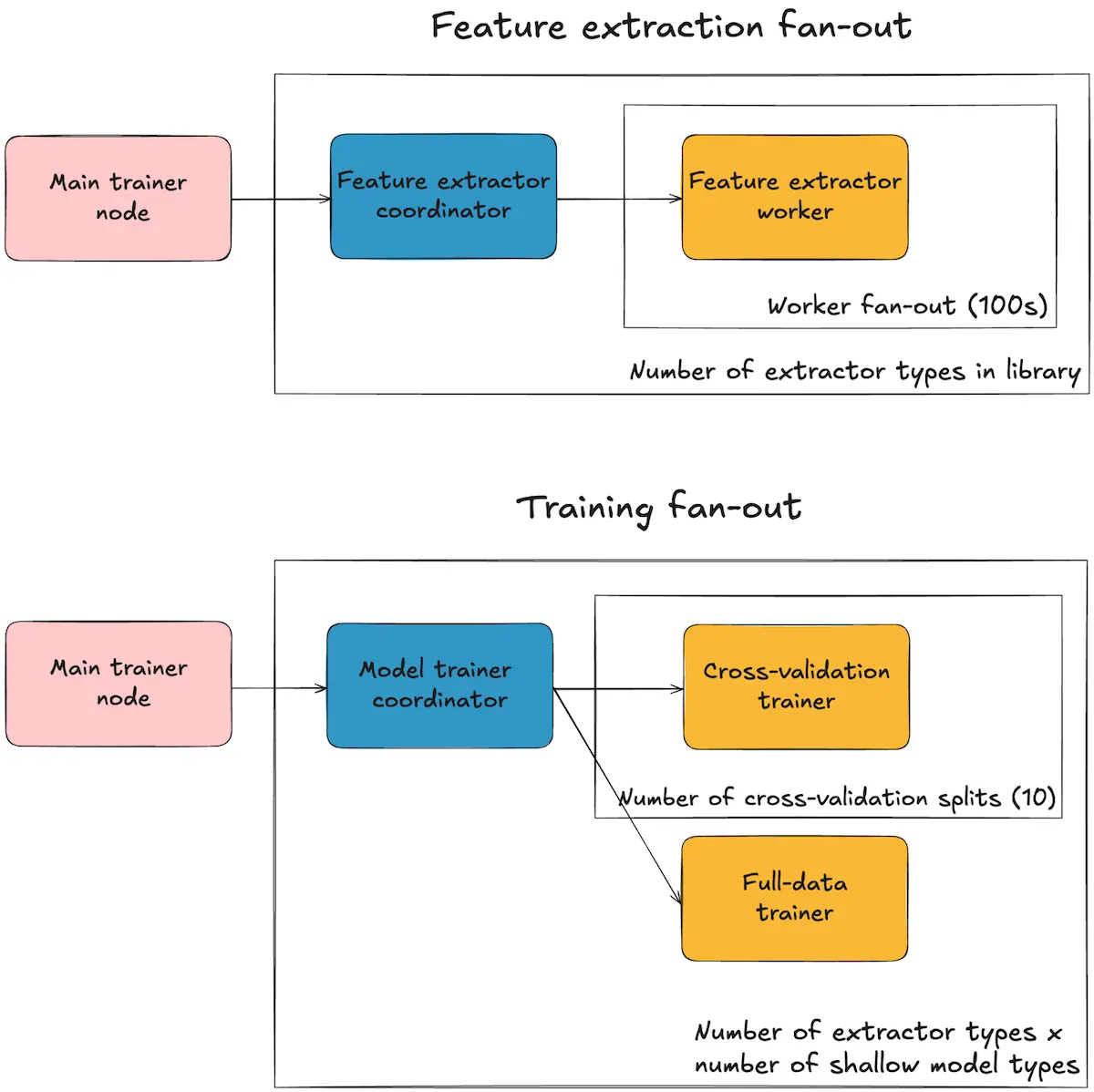
Model Training
For every feature-model combination:
- With 4 feature types and 5 model architectures, we launch 20 trainer coordinators
- Each coordinator implements 10-fold cross-validation for reliable performance estimation
- This means spawning 11 worker nodes under each coordinator:
- 10 nodes handle cross-validation folds (train on 90%, validate on 10%)
- The final node trains on all available data
- Cross-validation eliminates the need for manual data splitting while providing unbiased performance metrics
- The system tracks metrics for each combination (e.g., “DINOv2 + logistic regression: 95% accuracy”)
- We explore various shallow models including logistic regression with different hyperparameters, multi-layer perceptrons, random forests, XGBoost, and support vector machines
- The highest-performing combination becomes the production model
Deployment
Since our models are compact (a few kilobytes compared to 100s of megabytes), deployment happens without the overhead plaguing larger systems:
- Training completes in seconds to minutes (rarely exceeding 5 minutes even for complex datasets)
- Resources scale dynamically based on workload
- No cold-start penalties during inference
- Computing resources spin up and down on demand, drastically reducing operational costs
Pros and Cons of the Nyckel Approach
Pros:
- Training Speed: Massive parallelization (500x extraction, 200x training) cuts training from hours to minutes
- Iteration Speed: Feature reuse enables training iterations in seconds, creating genuinely interactive ML development
- Architecture Flexibility: Multiple feature extractors and model types allow exploration across diverse approaches
- Deployment Economics: Tiny model artifacts slash both latency and infrastructure costs
- Amortized Resources: Extractors are shared across customers, so costs associated with keeping nodes warm are amortized
- Extractor Adaptability: Different extractors excel on different datasets - sometimes CLIP outperforms newer models like DINOv2 depending on your data characteristics
- Data Required: Most models need as few as 13 training samples per class to achieve 80% accuracy.

Cons:
- Restricted to fixed feature extractors without neural network fine-tuning
- Results depend on how well pre-trained networks understand your data
- Theoretical ceiling on accuracy compared to fine-tuning approaches
- Compute-intensive during initial parallel training phase
Why We Chose This Path
We prioritized speed, scalability, and practical deployment over theoretical perfection. AWS Lambda combined with transfer learning creates an AutoML system optimized for real production environments, especially APIs. This unusual infrastructure choice distinguishes us from competitors who typically rely on slow and expensive GPU clusters.
And what about the fine-tuning approach and its theoretical higher accuracy? Well, fine-tuning sounds great in academic papers but falls apart in production: gigabyte-sized models, painful cold starts, and expensive always-on infrastructure make it impractical for many use cases. Similarly, Neural Architecture Search offers custom-fitted networks but introduces overwhelming complexity without leveraging existing pre-trained knowledge.
Our engineering team spent countless hours optimizing how we package Python code and neural extractors to enable seamless coordination across thousands of distributed nodes. That investment paid off: our performance matches or outperforms industry leaders, while also offering much faster training and deployment.

Conclusion
By embracing transfer learning and massively parallel Lambda architecture, Nyckel has made it possible to create high-accuracy, production-ready models in minutes instead of days (without sacrificing performance). We’ll continue pushing these boundaries as AutoML evolves.
Interested in learning more? You can get a custom demo here.