Multiclass vs Multilabel Classification: A 2025 Guide


Before creating a classification model, it’s important to define whether it’ll be multiclass or multilabel. But what’s the difference between the two? This article will cover the differences, when to use each, and what the top 5 vendors are for multiclass and multilabel classification.
Table of Contents
- What is classification in machine learning?
- What is multiclass vs multilabel classification?
- Multiclass vs multilabel checklist
- 5 best classification solutions
- How do I launch my own text classifier?
What is classification in machine learning?
Classification categorizes inputs into different groups (classes) based on their content. Inputs can include images, video, text , and tabular data.
Classification involves machine learning algorithms — specifically deep learning models like Convolutional Neural Networks (CNNs) — that identifies patterns and assigns them to the most applicable category.

These models are built using annotated (pre-labeled) training samples. Once trained off this data, you can feed the model new images and have it categorize them. Alongside the label, the model provides a confidence level (0 to 1) indicating its certainty in the classification.
Use cases of classification include:
- Is this email spam? (Yes / No)
- Is my flight likely to be delayed? (Unlikely / Likely / Very Likely)
- What colors are in this image (Red / Blue / etc.)
- What species of dog is this? (Dalmatian / Pug / etc.)
Test it yourself with our brand sentiment classifier
Just input text into the below box, and it will classify it as positive, negative, or neutral.
What is multiclass vs multilabel classification?
Classification relies on predefined classes (or labels). For each you’ll outline:
- The # of available classes
- If the data can tagged with just one label, or 2+
The difference between multiclass and multilabel refers to how many labels the input can be tagged with. With multiclass classification, the model will always return just one predicted label (i.e., the tags are mutually exclusive).
With multilabel, the model can return 2 or more labels (if relevant).
What is multiclass classification?
With multiclass classification, the model will select just one winning label. A classifier that identifies car makes, for instance, will only output one label.

This is often used where there’s a clear taxonomy, such as species or item identification. This recycling materials, for example, analyzes an image to determine its material type and then identify if it’s recyclable or not. It uses multiclass classification because a glass bottle cannot be both glass and paper.

An additional example using text involves social media moderation and flagging text as not offensive, offensive, and hate speech. As something can’t be both “not offensive” and “hate speech”, only one label will be selected at a time.

What is multilabel classification?
With multilabel classification, the model has the option of outputting multiple labels if relevant. The classifier below, for example, identifies what kitchen finishing styles are present. Since the drawers and cabinets have different finishings, the image is tagged with multiple styles.

Color classification is another use multilabel use case. Let’s say you own a retail site and want customers to be able to search items by color. A classification model is a great way to identify an item’s color without manual tagging.
Given that clothing is often not monochromatic, though, you’d likely want to use multilabel classification. That way if a shirt has both blue and red shades, it would appear for either a ‘blue’ or ‘red’ filter.

Another example using text involves topic or thematic identification. In the below text, for example, the user has mentioned both breweries and restaurants and thus gets tagged with both topics.

Are there other types of classification models?
Yes, alongside multiclass and multilabel, there is a third type: binary classification.
This is like multiclass, in that the model selects just one winning label, but the difference is around the number of label options. With binary, the model is selecting between just two class (Yes/No, Spam/Not Spam, etc.). Multiclass, meanwhile, refers to models with 3 or more classes.
Binary classification can be as simple as “snowing or sunny” to something more complex like “does this asset contain my brand logo or not?”

Do you have a simple visualization of this?
Yup! Here’s a table outlining the differences between the three types.
| Binary | Multi-Class | Multi-Label | |
|---|---|---|---|
| Use when | The image can fall under just 1 of 2 predefined categories | The image can fall under just 1 of 3+ predefined categories | The image can have multiple non-exclusive tags. |
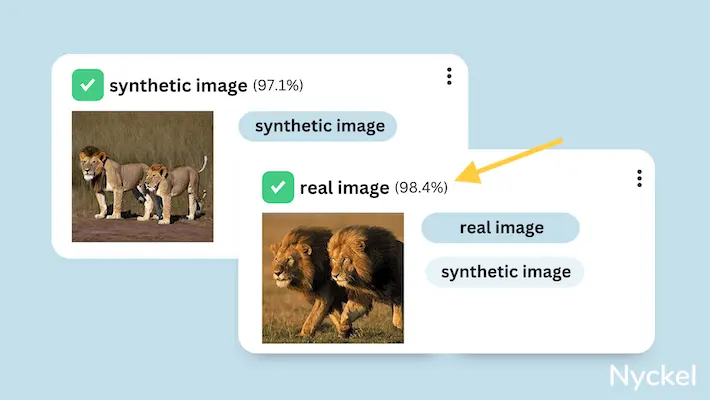
| Use cases | Identifying if an image is AI or not | Identifying flower species | Tagging what clothing items (pants, shirts, jacket, etc.) are in each product image |
How does the model decide when to return multiple classes for multilabel?
As mentioned earlier, classification models will return a confidence score with their selections. These range from 0 to 1 and represent how confident the model is that it’s right (1 being extremely confident).
With binary and multiclass classification, the predicted label will always be the one with the highest confidence score. So, in a yes/no binary situation, the class with, say, 0.500001 or higher will win.

With multilabel, each label’s confidence score is calculated independently. There’s no winner at the expense of another. Because of that, it’s important to set a minimum confidence threshold that needs to be crossed to tag that label.
As an example, your threshold could be 0.7. This means that the input won’t get tagged with that label unless the model’s confidence score for that class is 0.7 or higher.
This would be calculated separately for each class. It’s possible, then, that an input could be tagged with all or none of the labels.
It’s important to note that you could also implement a minimum confidence threshold for multiclass models. If the winning label’s score is lower than that, then the model’s prediction would be ignored. While possible, this is not common nor a must like it is with multilabel.

There is no golden rule for the right threshold. It’ll be influenced by the model’s general accuracy and what’s at stake for false positives.
How does annotation differ between multiclass and multilabel?
Annotation differs substantially between multilabel and multiclass.
With binary or multiclass, each input will have one label. While there’s of course the risk of mislabeling, annotation auditing is easy: you merely check whether the input has a label or not.
Multilabel annotation, however, is more arduous and riskier. This is because:
- If a label is tagged, the model is trained that it’s there
- If a label is not tagged, the model is trained that it’s not there
So, not only do you need to add the right tag(s), like with multiclass, but you also must be careful about false negatives (where you don’t tag something when you should).
Let’s use the below image. Say you’re trying to train a model to identify product colors.

When annotating, you may be tempted to just tag pink and red, since that’s the dominant color he’s wearing. But there’s also an orange background and a black shadow. If you don’t tag orange and black here, it could confuse the model.
This can be fixed by normalizing the background (where every image has an orange background, or you do background removal first), but the example nonetheless highlights the annotation risks of multilabel.
For multilabel, can I throw in 100s of things to look for?
It depends. Do those labels share a common theme? There’s a big difference between a model choosing between 60 unique colors and one that contains 30 color types, 20 clothing types, and 10 age brackets.
To better illustrate this, let’s use the online retailer example again. You want customers to be able to filter items by the clothing type (shirt, pants, dress, jacket) and age group (baby, kids, teens, adults). For both sets, the labels are mutually exclusive (an item can’t be both baby and adult)
While it’s tempting to throw all these labels into one model, we don’t recommend this path.

Why?
Because it runs counter to the engineering best practice of writing clean code. A function should strive to do only one thing. If you can break up a function into smaller pieces, then you should.
This concept applies to machine learning too.
If the label set can be broken into smaller sets (e.g., clothing type and age group), then you should break them into separate models. In the above case, that would involve two multiclass models (age, type) versus one massive multilabel model.
The key reason is model management and fine-tuning (the practice of improving the model). With multilabel - due to the aforementioned annotation differences - there is a heightened risk of poor annotation, which could then confuse the model.
For example, let’s say the model has great accuracy with the age classes, but terrible for type. If you had two models, you focus just on improving the type model, using image samples with a single label.
When all classes are bundled together, though, fine-tuning is more complicated. Not only do you have to add more samples for type, but you must ensure those samples also have the correct age labels. If you forget to add those, the age model (which was working well) runs the risk of no longer being accurate.
Can I hack multilabel classification using multiclass or binary classification?
Yes, and it’s not necessarily a bad idea. There are two methods:
Use different binary models for each label
Instead of doing multilabel, you could create a unique binary classifier for each class (using Yes/No).
If you have 20 classes, for example, then you would send 20 separate requests to 20 different models, one for each label.
Using colors, that could look like:
- Red or Not red
- Blue or Not blue
- Yellow or Not yellow
- ….etc. until you have 20 binary responses for all 20 colors
You’d then collect your responses to determine what colors are in each image.

The pros include:
- Easy to identify holes in the model. Isolating models makes it easier to see what classes have poor accurate rates.
- Easy to fix those holes. Multilabel annotation comes with a heightened risk of false negatives. Separate binary models mitigate this risk and keeps the algorithms separated.
The cons include:
- More overhead. Managing 20 different binary models could become difficult.
- Costs. 20 requests vs 1 could become cost-prohibitive at scale.
Use a multiclass model’s confidence scores
While multiclass classification is all about selecting one winner, models can still respond with what labels were close contenders (as measured by confidence scores).
You could mine these results for additional insights. The below color classifier, for instance, is multiclass and correctly predicted that blue was the dominant color. Diving into the labels that were close contenders, you can see that it correctly identified the other major colors: green, black, and brown.

One path, then, is to analyze the confidence scores of the non-winners and incorporate as many colors that add up to, say, a 0.9 score.
Does measuring performance differ between these two model types?
Yes, it does.
Multiclass models are commonly measured by the overall accuracy (the % of times the model labeled the data correctly). This is often visualized via a confusion matrix.
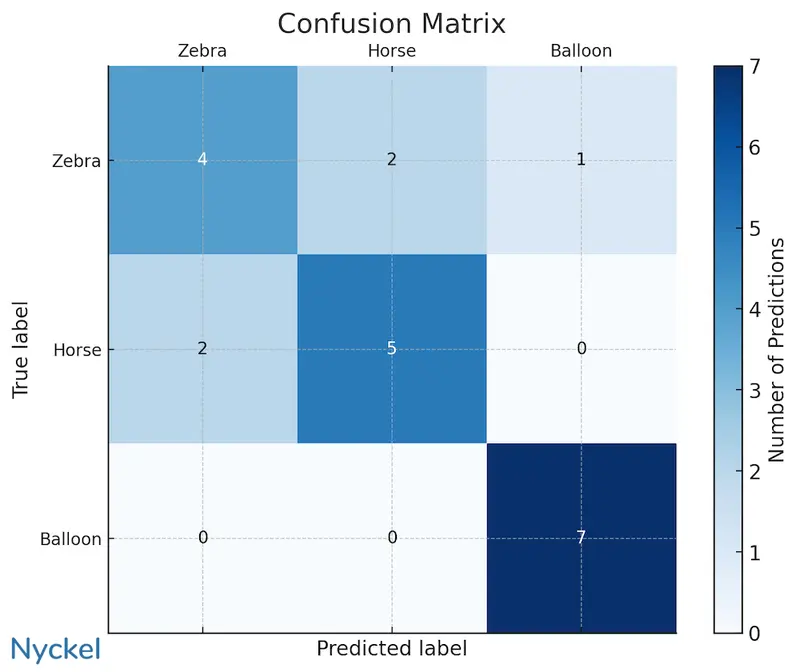
Additional performance metrics include recall and precision, which look at the performance of individual classes.
| Accuracy | Recall | Precision | |
|---|---|---|---|
| What it measures | The % of times it selects the right label across all images. | The % of times it selects the right label across images in a specific class. | For a specific label, the % of times it predicted it correctly versus all times it picked it |
| Useful for understanding | The overall accuracy of the model. | The accuracy within a certain class. | How reliable the model is for a specific class. |
With multilabel, the overall accuracy metric is not commonly used since the labels are calculated independently. What’s more important is understanding the precision/recall of individual labels.
An additional multilabel metric is Hamming Loss, which measures the fraction of the wrong labels to the total number of predictions. Like with a confusion matrix, this makes it easy to visualize holes in a model.

Checklist to determine when to do multilabel vs multiclass classification

Choosing between them isn’t always straightforward. Below are a few guidelines.
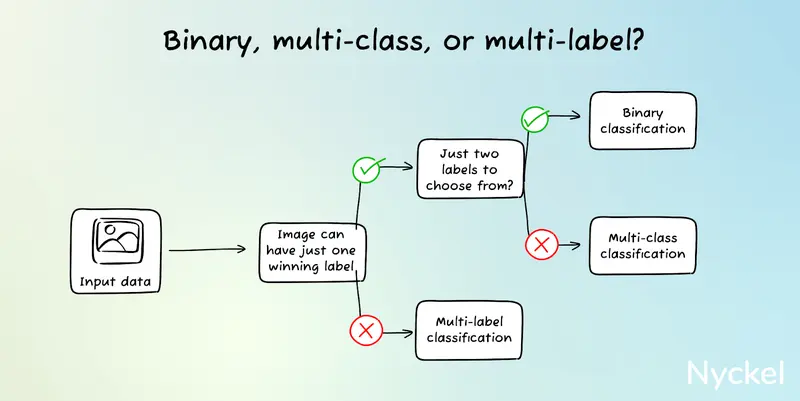
1. Can an input have just one unique label?
If yes, then use multiclass. You’ll always use multiclass when the labels are mutually exclusive.
2. Do you have multiple sets of mutually exclusive label groups?
If yes, then use multiple multiclass classifiers for each set.
3. Do you have classes with a similar theme and you want to tag the input with multiple labels if applicable?
If yes, then multilabel is likely your best approach.
5 Best Classification Solutions
1. Nyckel
Nyckel provides a classification API for easily deploying both multiclass and multilabel models at scale.
Pros:
- Real-time training - The model automatically updates after every change, making it easy to train and improve.
- Elastic Pricing - You only pay for usage versus nodes, by-hour, etc.
- API-approach - Nyckel provides a developer-friendly building environment.
- Streaming API - Unlike other batch API tools, Nyckel’s API offers real-time creation of functions, uploading samples, and invoking.
Cons:
- Not as many features as other solutions - For instance, they don’t offer unsupervised classification.
- No customization of the algorithm - The decision to abstract the machine learning complexity does mean there’s no way to adjust the foundational model algorithm.
2. Google Vertex AI
Google Vertex AI is Google’s unified data and AI platform. While powerful, it comes with a steep learning curve, and the initial setup and labeling process can be complex. Still, its integration with the broader Google ecosystem can be advantageous for those willing to invest time in the learning curve.
Pros:
- Rich library of help docs - Google does a great job at creating explainer videos and guides if you get stuck. Additionally, there’s a broader Google community that actively shares ideas and recommendations.
- Backed by Google - Nobody got fired for buying from Google. It’s a safe route, even if not the easiest.
Cons:
- Steep learning curve - Unless you are already well-versed in Google’s developer products, their dashboard can be difficult to navigate.
- Slow to train / build - Each time you want to train, even for a small dataset, it can take hours. Larger datasets can take 24 hours or more. This makes real-time fine-tuning impossible.
3. Keras / Tensorflow / PyTorch
These three tools are all open-source machine learning frameworks. They make building your own machine learning model simple, but they don’t abstract it completely, so you still need a deep understanding of ML to launch.
Pros:
- Control - You can adjust nearly all parts of the model. Compared to the AutoML vendors on this list, you have much more control over the nuances of the algorithm.
- Cost-effective - Outside of opportunity cost, hosting your own model tends to be cheaper than a third-party vendor.
Cons:
- Requires ML experience - If you don’t have a machine learning background, it’ll be hard to get going.
- Time-consuming - Even if you have ML experience, there’s a major time and effort commitment.
4. Amazon Comprehend

For text classification, Amazon offers its own natural language processing solution called Comprehend. While the setup process can be tedious, the platform’s interface simplifies the training process. However, it does require coding for deployment, so it’s not ideal for those without coding expertise.
Pros:
- Great for ML experts - Amazon provides granular controls for manipulating your algorithm and models. If you know how to work them correctly, you get a lot of flexibility.
- Backed by Amazon - You can trust that Amazon will continually improve their product and offer extensive integration guides.
Cons:
- Arduous set-up - Unlike more turnkey AutoML vendors, Comprehend is confusing and time-consuming to set-up. Deployment often requires complicated coding versus a simple API call.
- ML experience is not a must, but it’s recommended - The flipside of a robust feature set is that managing them can be difficult unless you understand ML well.
5. Hugging Face AutoTrain
Hugging Face AutoTrain allows you to quickly build image classification models through their open-source tool. It offers pretrained models and fine-tuning options, making it suitable for various applications.
Pros:
- Integrated with the Hugging Face ecosystem - Hugging Face is major playing in the ML space, with a large community that uploads free models, ideas, and datasets.
- Great for open-source lovers - Hugging Face makes it easy to publish your models to the open web, allowing you to share and solicit feedback easily.
Cons:
- Still requires some technical knowledge - You can view Hugging Face as the Github of Machine Learning. Just as Github requires some basic technical know-how (such as how to spin up a repo and edit code), Hugging Face requires some basic coding skills.
- Focused on open-source - Businesses that want a more hands-on, closed experience may not enjoy Hugging Face’s open-source philosophy.
How to get started with multiclass or multilabel classification
Nyckel - a machine learning tool specifically for classification - makes it easy to build both multiclass and multilabel models. It takes just a few minutes, and the tool can build an accurate model with as a few as 10 samples per label.
You can try it for free here.