ModernBERT: Surprisingly Ineffective for Transfer Learning

Choosing the right ML model architecture is essential for hitting your target accuracy. With so many models available, the process can feel overwhelming, but performance benchmarks provide a helpful way to narrow down options and focus on results.
In this article, we spotlight one model in particular: ModernBERT. By benchmarking its performance across 146 text classification datasets, we evaluate how it compares to other leading models.
What is ModernBERT?
Focused on processing text, ModernBERT builds on the original BERT model by updating its training techniques and using more recent data. It also incorporates advanced training practices that help it capture nuanced language patterns and evolving expressions. Given this, ModernBERT in theory should deliver more accurate and robust performance in tasks like translation, sentiment analysis, and question answering.
In our analysis, though, this wasn’t the case, and in no dataset did ModernBERT deliver better accuracy than the next-best model.
This was surprising, given the hype around it. Below dives more into the results.
Who is Nyckel
Nyckel is an AutoML platform that makes it easy for anyone to build custom ML models without needing a PhD. The Nyckel platform auto-tests your dataset against hundreds of model architectures - including ModernBERT - ensuring your ML model hits the highest accuracy possible.
Nyckel publishes these benchmarks to help engineers understand the effectiveness of popular models, which can be useful for prioritizing what to test.
Methodology
We ran the benchmark on 146 text classification datasets from our production database. We used transfer learning, where the models were used as feature extractors on top of which we then trained and evaluated logistic regression classifiers.
In addition to the ModernBERT base model, we tested these models:
- DistilBERT base. DistilBERT is a distilled down (smaller) version of the popular BERT model. It’s a solid general-purpose model.
- DistilBERT sst-2. This is a DistilBERT model fine-tuned on the SST-2 dataset, which is a large text sentiment dataset. It tends to be best at English sentiment classification tasks.
- NLPTown multi. This BERT-based model is finetuned on product reviews in six languages.
- Neuralmind pt. This model is finetuned on the Brazilian web corpus and tends to do very well for Portuguese and Spanish language tasks.
- STrans multi-v2. This model is designed to handle 50 languages. Sentence transformer considers sentence-level context rather than token-level context which BERT models use. This is our highest performance extractor as shown in this benchmark.
- BAAI bge-base. This model uses flag embeddings which complement both BERT and sentence embeddings. It tends to do well across the board.
We then measured how often each model “won” over the others (meaning had the highest accuracy).
Results
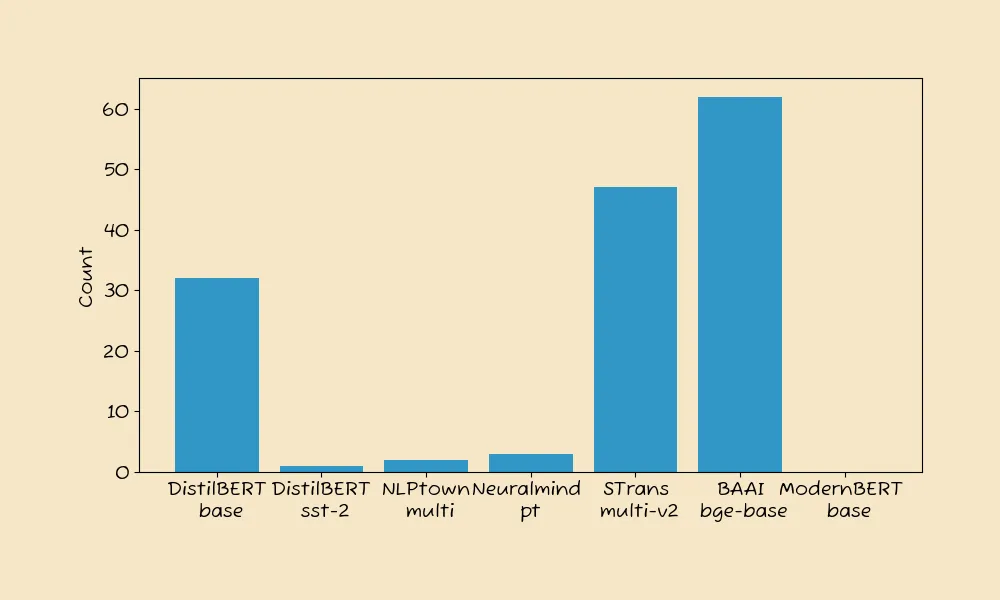
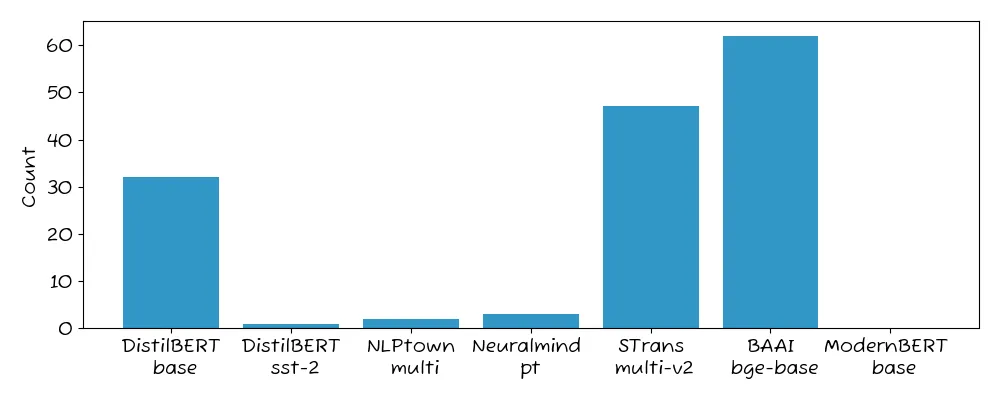
Across the 146 datasets, ModernBERT was the best model in ZERO cases.
In general, we never see a model win all - and rarely do we see a new model not win one. But in this case, ModernBERT won 0% of the time.
Across all datasets, we saw:
STrans multi-v2: 42%BAAI bge-base: 33%DistilBERT base: 21%Neuralmind pt: 2.1%NLPTown multi: 1.4%DistilBERT sst-2: 0.7%ModernBERT base: 0%
What the results tell us
The numbers highlight that ModernBERT is likely not the best model to test first. Our text datasets are quite diverse - from text sentiment to NSFW to product keywords - and it still didn’t win any.
Does that mean ModernBERT is not worth testing? No. It’s always possible that any model - especially a new one - will perform better on a subset of your data. But in our testing, STrans multi-v2 and BAAI bge-base would be the ones to try first. If you do want to use ModernBERT, we recommend that you fine-tune the model on your data rather than using transfer learning as was done in this benchmark.
How to find the right model for your data
We do recommend using an AutoML solution to build your ML model. By testing hundreds of models at once, you’ll maximize your chances of finding the best model for your data.
If you want to learn more about Nyckel’s AutoML tool - please reach out to us here.