How much training data is needed for classification?

- Only 10-15 samples per class are required for a production-grade classifier
- Over 10,000 production classifiers analyzed
- 89% mean accuracy across them
- Held true across input types and industries
- More data is needed for granular (fine-grained) tasks
When it comes to training data, the industry consensus is that more is better. But how much training data is sufficient? Do you need 10, 100, or 1 million training samples per class to get a production-level model? And does that differ by industry or input type (text, image, etc.)?
To answer this, we analyzed over 10,000 image and text classification functions from our database. We trained multiple models on subsets of the training data and measured how the accuracy improved as we added more samples.
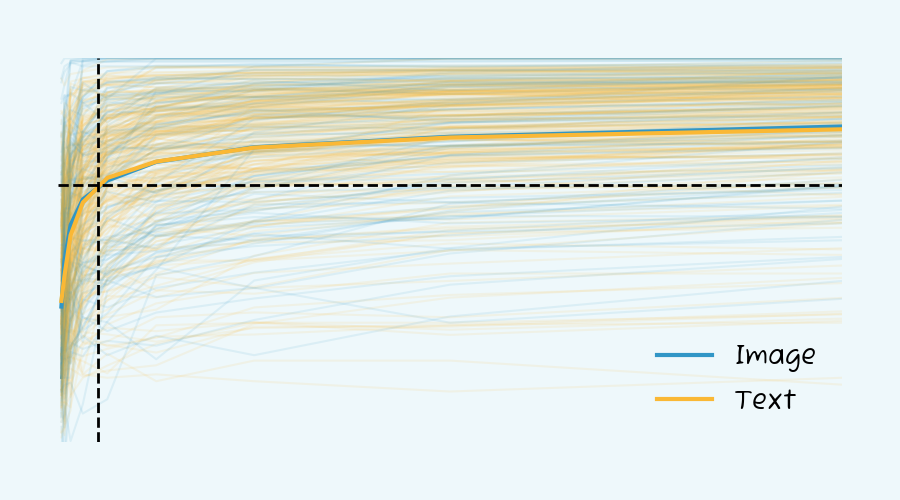
The results were surprising. You need only 13 training examples per class to train a solid image or text classifier. That’s a lot less than the 100s or 1000s of samples that are often cited.

As you can see, the more training examples you have, the better the model performs. But, the rate of improvement significantly decreases as you add more examples - with a plateau between 85%-90% after 100 samples.
And if ~90% is the mean ceiling, then let’s consider a model to be production-level when it’s 90% toward that plateau, which would equate to roughly 80% mean accuracy. That corresponds with needing just 13 samples per class.
While your target accuracy will depend on your needs, the data highlights, at the very least, that building a “solid” model doesn’t require a daunting number of training samples.
(As an aside, we recommend continuous improvement and monitoring of the model too. See, for example, our integrated active learning feature: Invoke Capture.)
Methodology
We used a common approach called “fine-tuning” throughout this analysis. The data (images or texts) were first passed through large pre-trained Deep Neural Networks (LLM). For image models we used one of the CLIP models from OpenAI, and for text we used a Sentence Transformer from Huggingface.
These deep networks are trained on large datasets (millions of images or text) and have learned to extract useful features from the data. We then fine-tuned these networks on the smaller dataset using Logistic Regression.
For each dataset, we selected a balanced set of classes and split the data into training (80%) and test (20%) sets. We then trained the models on the training set and evaluated the accuracy using the test set. We repeated this process for different training set sizes and plotted the results.
Differences between text and image models
We saw almost no difference between image and text models in terms of samples needed. This was surprising to us, given that text is often thought to require more data than images.
Differences between industries
The data was collected from many industries: IoT, ad tech, sales, retail, marketplaces. While we saw some differences, they were minor. In all cases we hit the 90% mark with 10-15 samples per class.
Difference between tasks
As expected, the biggest signal of samples needed was task complexity. For example, basic classification among well-defined classes requires fewer samples than fine-grained classification among similar classes.
In other words, a “car vs bus” classifier may need just 1-2 examples for solid performance, while a nuanced classifier of 200 similar-looking food items may need many more.
Difference between training methods
There are many ways to train image classifiers. On one extreme no training is needed at all, e.g. by just asking a multimodal LLM. On the other extreme are more methods like Neural Architecture Search (NAS) where a large set of architectures are explored and tuned to your data. The present analysis and conclusions are based on the fine-tuning approach detailed above, and does not generalize to other methods.
Conclusion
Building a working model doesn’t take 1000s of samples per class, or even 100. Our data revealed, instead, that all you need is 10-15 training examples per class. This held true across industries and inputs, although more samples are generally needed for fine-grained classification.
This is great news for those with limited training data, as it means you can more quickly launch, iterate, and improve your models.
Of course, the exact training samples you’ll need depends on your model, classes, and target accuracy. The only way to know for sure is through testing.
If you haven’t launched your model yet, we recommend looking into Nyckel, which makes it easy to build production-level classifiers in just minutes. Your accuracy score automatically updates after every change, allowing you to quickly see the impact of new samples.
At Nyckel our AutoML engine includes the fine-tuning method used in this study (along with many other methods). This allows you to develop a production-grade classifier in minutes, and then improve it over time with additional samples.