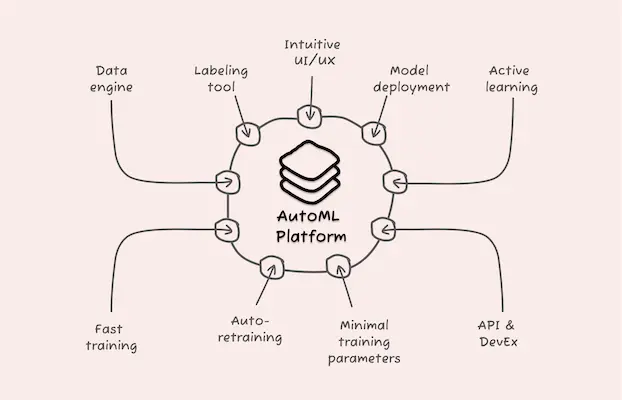
9 Must-Have Features for Your AutoML Platform: A Comprehensive Guide

In our previous post, What is AutoML? A Comprehensive Guide & What It Means for Product Teams, we discussed the concept of AutoML and how it’s democratizing machine learning (ML). AutoML streamlines ML model creation by taking your annotated data and producing a model, automating tasks like model architecture selection, hyperparameter tuning, and performance evaluation. In this way, AutoML makes the creation of ML models faster, more efficient, and accessible even to those without ML expertise.
Then, in our post End-to-End AutoML: Your AutoML Platform Should Span the Entire ML Development Pipeline, we discussed why AutoML needs to be more than just training a model; it should span the entire ML development pipeline.
In this post, we explore nine features to consider when choosing an end-to-end AutoML platform.
1. Data engine
A data engine enables you to manage an ML model’s training data by helping you find problem cases that illuminate 1) where your model is making bad decisions and 2) where you’ve incorrectly annotated data. It supports the iterative loops that are necessary to find this problematic data and then retrain your model with newly annotated data.
This data-centric approach to ML, as advocated by Andrew Ng, emphasizes that focusing on data quality is the best way to create a good model and that improving data quality is an iterative process. With the support of an AutoML tool with a robust data engine, continuous improvement of ML models becomes a streamlined process, leading to models that produce more accurate and reliable outcomes.

2. Labeling tool
An AutoML platform should offer an in-built labeling tool that is tailored to the machine learning task at hand, whether that’s text classification, object detection, or something else. A specialized labeling tool streamlines the annotation process, allowing you to label data faster and more accurately. This enables you to create more high-quality annotations, which are crucial to creating a good model.
When selecting an AutoML platform, look for a labeling tool that seamlessly integrates with the platform’s data engine, as this will make it easier for you to make quick and iterative updates to data. An in-built labeling tool prevents you from needing to switch between tools, reducing development friction and providing a better user experience.
3. Model deployment
Model deployment isn’t a trivial task. It involves steps such as choosing the optimal hardware for your latency and throughput needs, optimizing the model for peak performance on that hardware, ensuring it can handle varying workloads, and seamlessly integrating it into your existing system. To simplify this process, it’s important to select an AutoML solution that covers model deployment.
When selecting an AutoML platform, ensure it offers a deployment option with a pricing model that suits your needs, whether elastic or continuous instance running. It’s also smart to verify if the platform provides appropriately-sized hardware for your model deployment, as the available hardware directly influences cost, latency, and throughput optimization for your model. The hardware should also be scalable to efficiently accommodate usage patterns and unexpected spikes in demand, while avoiding unnecessary costs during idle periods.
4. Active learning
Active learning is the process of finding and annotating informative data to improve your model. Focusing on informative data instead of just randomly chosen data provides better results for your time spent on annotation. It’s important to do this periodically throughout the lifecycle of your model to handle data drift, new edge cases, class imbalance, or a lack of generalization. Ideally, your AutoML platform would automatically capture these important data points when a deployed model is invoked - a process we call “invoke harvesting”. This enables adaptive model maintenance and retraining, which are essential for maintaining and improving model performance.
Active learning through invoke harvesting offers several important benefits:
- Data drift mitigation: Data distribution in the production environment may change over time, leading to data drift. By continuously harvesting and labeling data through invoke harvesting, you can retrain your model to address data drift effectively.
- Balanced class representation: Invoke harvesting can automatically capture data from underrepresented classes, allowing you to retrain your model to perform better on those classes.
- Enhanced model generalization: By gathering low-confidence data points and data points similar to those where the model failed, invoke harvesting enables you to retrain your model on diverse data, enhancing its performance across a wide range of data.
5. Fast training
Training speed is a crucial factor to consider when conducting an AutoML tools comparison. You can test training speed across platforms you’re evaluating using a sample dataset, like we did in our image classification benchmark. Fast training offers several benefits that enhance the entire ML development lifecycle:
- Faster iterative workflow: Speed plays a pivotal role in the iterative loops of ML development. When models can be trained and deployed in seconds, development teams can gain rapid insights into improvements and annotation errors, accelerating the feedback loop.
- Reduced time-to-production: Faster development cycles enable teams to bring ML models to production quickly, resulting in a higher return on investment and a competitive edge in the market.
- Enabling continuous deployment: Just as continuous deployment is a best practice in software development, ML development is starting to embrace this approach. Fast iterations in the ML lifecycle, from model training to deployment, facilitate seamless continuous deployment, enhancing team productivity.
- Enable creating separate functions for each of your unique customers: When a new model can be trained in seconds from a handful of annotated examples, you can easily create custom models for each of your customers that handle their unique data.
In our image classification benchmark comparison, Nyckel trained a model in just around 1 minute, compared to ~12 minutes for HuggingFace and ~5 hours for Google. Nyckel also supports low latency and invokes with elastic scaling, making it a top-performing option for rapid model deployment and integration into applications. On top of that, even with our recycling identifier, which has over 10,000 recycling samples, training took less than a minute.
6. Auto-retraining
Auto-retraining is a critical capability to look for in an AutoML platform. ML models are not static entities; they require continuous updates and improvements to remain accurate and relevant. By choosing a tool that enables auto-retraining, you can proactively address model errors and minimize the need to build complex data pipelines for the retraining process.
Auto-retraining offers several important benefits:
- Continuous model improvement: Auto-retraining allows you to take advantage of new data and feedback to continuously improve your model’s performance. By leveraging up-to-date information and newly annotated data, ML models can deliver more accurate and relevant results.
- Streamlined model maintenance: Automating the retraining process simplifies model maintenance, reducing the manual effort required for regular updates.
- Minimizes data pipeline complexity: Building data pipelines for manual retraining can be complex and time-consuming. Auto-retraining reduces the need for intricate pipelines and streamlines the process of incorporating new data for model improvement.
7. Minimal training parameters
Choosing an AutoML platform with minimal training parameters eases parameter anxiety by reducing the worry of selecting optimal values. Users can rely on experts or automated hyperparameter sweeps to handle parameter selection, fostering a more confident and streamlined model training process. With less time spent fretting over parameter choices, you can focus on the core aspects of model development, enhancing your productivity and overall experience with the platform.
An AutoML platform that requires fewer parameter inputs from you also reduces the likelihood of making mistakes in selecting the right values. By simplifying the decision-making process, users can avoid potential errors and achieve more accurate and effective ML models. Emphasizing simplicity in parameter selection can lead to a user-friendly AutoML experience, catering to both novices and experienced data scientists, while ensuring the development of high-quality models without unnecessary complications.
8. API and developer experience
A platform with an intuitive, well-documented API empowers developers to efficiently leverage AutoML capabilities, while the ability to create custom functions allows developers to tailor ML solutions to suit specific requirements.
When examining the API and docs for an AutoML platform, here are some qualities to look for:
- Intuitive and easy to use: An intuitive and easy-to-use API simplifies the development process and makes it faster and easier to integrate ML capabilities into your applications.
- High-quality documentation: Clear and comprehensive documentation helps developers understand the API’s functionalities. Well-documented APIs enable quick and efficient implementation and reduce the learning curve for using the platform.
- Ability to create new functions: A flexible API that makes it easy to create new functions will enable you to create custom ML features for individual customers or specific use cases.
9. Intuitive UI/UX
An intuitive and well-designed user interface (UI) is essential for an efficient AutoML platform that seamlessly transitions between the stages of model development. Model deployment is an iterative process, so you’ll frequently revisit steps like data labeling, model training, evaluation, and deployment while refining your model. Fast iteration is crucial so that you can easily experiment with different model options, identify optimal solutions, and quickly deploy refined models. A well-designed UI/UX in an AutoML platform facilitates this by providing intuitive controls that promote rapid experimentation and effective model refinement.
A robust UI/UX should easily support actions, including:
- Adding data: The platform should ensure a user-friendly data ingestion process that allows users to effortlessly upload and import datasets, while also providing clear instructions and guidance on supported data formats and options for seamless data integration.
- Annotating data: The platform should implement an intuitive annotation interface that simplifies the labeling process for ML training data. It should also offer interactive tools for easy labeling, such as dropdown menus for categorical data.
- Iterating on data and retraining: The platform should enable a smooth transition between data annotation and model retraining workflow. It should also offer versioning and tracking features to keep a record of data changes and model performance improvements.
- Checking model performance: The platform should present model performance metrics and insights in a user-friendly dashboard for quick and easy interpretation. It should also provide visualization tools to assess model predictions and understand areas for improvement.
By bringing all these aspects together in an intuitive and cohesive UI/UX, an AutoML platform can empower users to seamlessly navigate through the data annotation and model training processes. This integration not only streamlines the workflow but also enhances the overall user experience, making the AutoML platform more accessible and effective for both users without ML expertise and experienced data scientists.
It all ties in together
The sum of all the above is greater than any individual part. For instance:
- The combination of a data engine and data labeling capability enables quick and efficient iterations on data, fostering continuous improvement in model accuracy.
- Model deployment, when coupled with invoke harvesting, ensures the capture of important samples and provides valuable insights to handle data drift effectively.
When conducting an AutoML tools comparison, it’s critical to consider how these individual components contribute to the overall experience. The interaction between each component streamlines the entire ML development lifecycle, from data preparation to model deployment, resulting in an intuitive and user-friendly experience that accelerates the journey from ML idea to successful implementation.
We built Nyckel as an end-to-end AutoML platform, so you can train and deploy machine learning functions without writing code or dealing with infrastructure. Explore Nyckel’s quick starts and sign up for a free account to get started. Reach out to us if you have any questions about how Nyckel could work for your use case.
This post is the final post in a series of articles about AutoML and what it offers organizations looking to implement ML. The first article of this series was an intro to AutoML and the second article examines the concept of End-to-End AutoML.